此篇博客为本人对的总结。
关于Scrapy的安装网上都有方法,这里便不再叙述。
使用Scrapy抓取一个网站一共需要四个步骤:
0、创建一个Scrapy项目;
1、定义Item容器;
2、编写爬虫;
3、存储内容。
本次爬取的目标是全球最大的目录网站,由于此网站数据过于庞大,我们这里只拿它的两个子网页做测试(手动捂脸)
我们需要爬取的是子网页 中的名单、超链接、名单描述。
---
0、创建一个Scrapy项目
首先打开cmd窗口输入以下命令将路径移到桌面(其他位置也可以)
cd desktop
然后创建一个Scrapy项目。继续在命令行中输入以下命令,(命令执行后请暂时不用关闭命令行,等下要用)
scrapy startproject tutorial
(创建一个新的Scrapy项目文件夹,文件夹的名字叫tutorial)文件夹中会有一个scrapy.cfg的配置文件和一个tutorial的子文件夹,tutorial文件夹中有如下内容:
0、__init__.py 这个不用多说,是模块的初始化,不用管
1、items.py 项目的容器
2、pipelines.py
3、settings.py 设置文件
4、spiders/ 文件夹,里面只有一个初始化文件__init__.py ,这里需要我们来完善。
等等文件(可能还有一些其他的文件,这里不多叙述)
1、定义Item容器
item容器是什么呢?item容器是保存爬取到的数据的容器,其使用方法和python字典类似,并且提供了额外的保护机制来避免拼写错误导致的未定义字段错误。
接下来我们要建模。为什么要建模呢?因为item容器是用来存放我们爬取到的网页内容,当爬取的时候返回的是整个网页的内容,而往往我们只是需要其中的一部分内容比如这里的网页 ,我们只需要他的书名、描述、与超链接。

所以这里我们需要改动item容器,打开 tutorial/item.py ,将其中的TutorialItem模块内容改为以下内容并写好注释:
class TutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() #标题 link = scrapy.Field() #超链接 desc = scrapy.Field() #描述
保存退出。
2、编写爬虫
接下来是编写爬虫类Spider,Spider是用户编写用于从网站上爬取数据的类。
其包含了一个用于下载的初始URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法。
接下来我们在Spider文件夹中新建一个叫 dmoz_spider.py 的文件,编写以下代码:(其中name是本次的项目名)
import scrapyclass DmozSpider(scrapy.Spider): name = "dmoz" #allowed_domains是为了防止在爬取的时候进入了其他网站 allowed_domains = ['dmoztools.net'] #初始爬取位置 star_url = [ 'http://www.dmoztools.net/Computers/Programming/Languages/Python/Books/' 'http://www.dmoztools.net/Computers/Programming/Languages/Python/Resources/' ] #定义一个分析方法 def parse(self, response): filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response,body)
保存关闭。代码解释(解释的不是很好,大概意思理解就行,不喜勿喷):
在本地目录下创建两个文件,叫做Books和Resource,然后将start_url中的两个初始网址提交给Scrapy引擎,Scrapy引擎中有下载器,会将网站的源代码下载过来,然后根据parse方法将下载的内容存放到Books和Resource中。
接下来继续进入刚才的cmd窗口,输入以下命令将路径切换到tutorial文件夹中:
cd tutorial
继续在命令行输入以下命令:
scrapy crawl dmoz
其中crawl是爬取的意思,dmoz是项目名。
然后输入回车执行。成功的话将会出现以下信息:

并且命令执行后在当前目录会生成两个新的文件,叫做Books和Resource。两个文件的内容就是爬取到的网站内容(即网站的源代码)。
3、存储内容
以往我们在爬取网页内容的时候都是使用的html的正则表达式,但是在Scrapy中是使用一种基于Xpath和CSS的表达式机制:Scrapy Selectors
Selectors是一个选择器,它有四个基本的方法:
xpath(): 传入spath表达式,返回该表达式所对应的所有节点的selector list列表
css():传入CSS表达式,返回该表达式所对应的所有节点的selector list列表
extract():序列化该节点为unicode字符串并返回list
re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表
存储数据之前我们先进去scrapy的shell窗口进行测试。继续对刚才的cmd窗口进行操作,输入以下命令进入shell窗口:
scrapy shell "http://www.dmoztools.net/Computers/Programming/Languages/Python/Books/"
目的是进入该网站的scrapy shell窗口,界面如下:
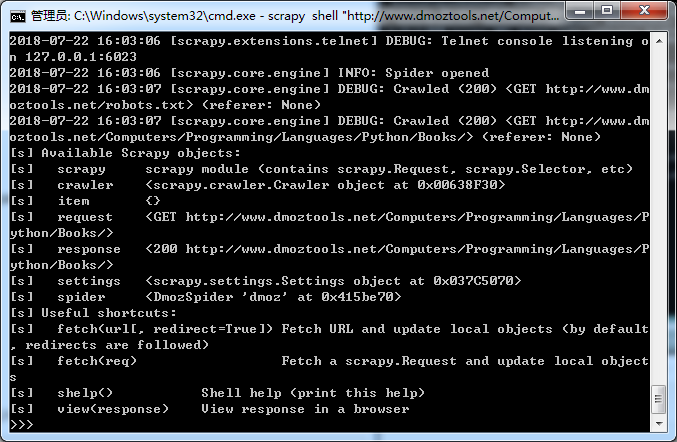
此时我们便可以对他进行操作。
其实这是返回我们刚才的response对象,我们可以对他进行一系列操作,比如response.body命令将会出现该网站的源代码,response.headers命令会出现网站的头配置等等
现在我们列举几个该对象的使用方法:
/html/head/title:选择html文档中<head>标签内的<title>元素;
/html/head/title/text():选择上面提到的<title>元素的文字;
//td:选择所有的<td>元素;
//div[@class='mine']:选择所有具有class='mine'属性的div元素。
此时shell窗口中还有 一个返回对象sel,接下来我们进行查找名单的测试。
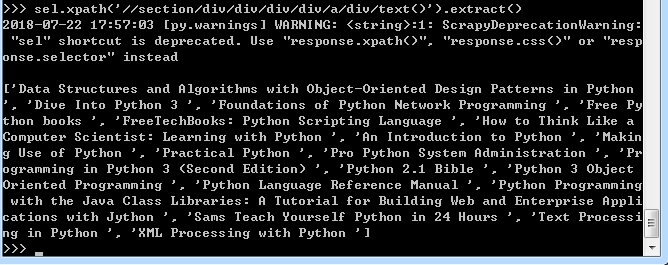
输入命令:(以下出现的路径请自行检查网页内容进行查看,右键点击网页对象选择检查即可出现)
sel.xpath('//section/div/div/div/div/a/div/text()').extract()
执行后将会返回网页中的所有名单,图如下:
同样,输入命令以下命令将会返回所有名单的超链接和描述
sel.xpath('//section/div/div/div/div/a/@href').extract() //返回超链接 sel.xpath('//section/div/div/div/div/a/div/text()').extract() //返回名单描述
好,测试完了之后我们来继续编写代码。
现在我们来对爬取内容进行筛选
打开编辑我们刚才编写的 dmoz_spider.py 文件,将内容改为以下内容
import scrapyfrom tutorial.items import TutorialItem #引入模块class DmozSpider(scrapy.Spider): name = "dmoz" #allowed_domains是为了防止在爬取的时候进入了其他网站 allowed_domains = ['dmoztools.net'] #初始爬取位置 start_urls = [ 'http://www.dmoztools.net/Computers/Programming/Languages/Python/Books/', 'http://www.dmoztools.net/Computers/Programming/Languages/Python/Resources/' ] #定义一个分析方法 def parse(self, response): sel = scrapy.selector.Selector(response) #分析返回的response对象 #//section/div/div/div/div/a/div/text() sites = sel.xpath('//section/div/div/div/div') #对内容进行筛选 items = [] for site in sites: #对爬取内容进行进一步筛选 item = TutorialItem() item['title'] = site.xpath('a/div/text()').extract() item['link'] = site.xpath('a/@href').extract() item['desc'] = site.xpath('div/text()').extract() items.append(item) #将筛选后的内容添加到列表items中 return items
保存退出。然后继续在cmd窗口进行操作,首先退出shell窗口:
exit()
随后开始爬取网站内容并将筛选后的数据导出,进行以下命令:
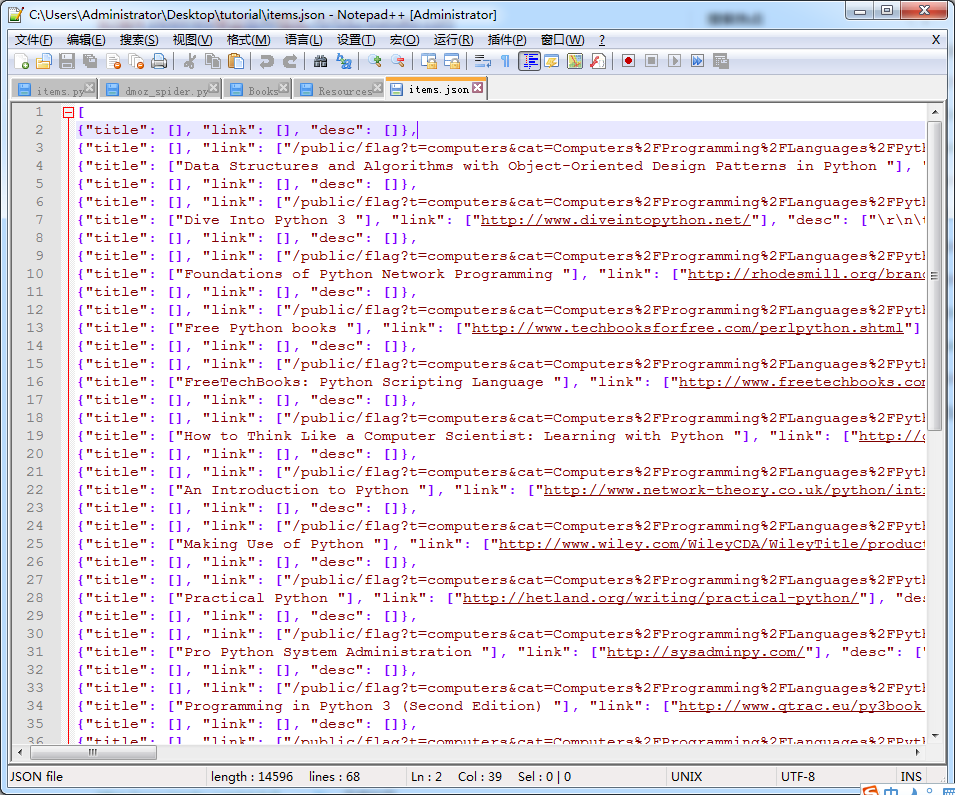
scrapy crawl dmoz -o items.json -t json
-o后面接导出的文件名;-t后面接导出的形式,形式常用的有四种:json、xml、jsonlines以及csv,这里我使用的是json。
执行后在当前路径会产生一个 items.json 的文件,我们使用文本编辑器打开它时会发现,里面就是我们本次要爬取的筛选后的内容:
本次爬取到这里便成功完成!
谢谢观看!(๑•̀ㅂ•́)و✧
我演了很多悲剧,到头来你们都说那是喜剧。 ------------------周星驰